通常情况下,可以通过调整采样比例,增加并行度得方式来加速收集统计信息。
总结一些小技巧:
1. 方法1- AUTO_DEGREE
为指定表定义一个特定的并行度
exec dbms_stats.set_table_prefs(user, 'BIG_TABLE', 'DEGREE', 8)让Oracle为你来决定并行度:
exec dbms_stats.set_table_prefs(user, 'BIG_TABLE', 'DEGREE', DBMS_STATS.AUTO_DEGREE)一个清晰且简单的方法是在全局级别设置该属性:
exec dbms_stats.set_global_prefs('DEGREE', DBMS_STATS.AUTO_DEGREE)2. 方法2 - CONCURRENT
首先,关闭并行执行:
exec dbms_stats.set_global_prefs('DEGREE', 1)CONCURRENT偏好参数允许DBMS_SCHEDULER一次启动多个统计信息收集任务,因此,数据库会并发的在多个表和表分区上收集统计信息。我们可以仅为自动统计信息收集启用该行为:
exec dbms_stats.set_global_prefs('CONCURRENT','AUTOMATIC')如果你启用了数据库资源管理计划,你可以为手动统计信息收集使用并发,或者手动统计信息和自动统计均使用:
exec dbms_stats.set_global_prefs('CONCURRENT','MANUAL')
exec dbms_stats.set_global_prefs('CONCURRENT','ALL')3. 方法3 - CONCURRENT and AUTO_DEGREE
同时启用CONCURRENT and AUTO_DEGREE,即多个任务将启动,且每一个任务潜在会启动多个并行查询服务,这会产生非常高的系统负载,酌情使用。你可以通过以下的方法,缓解启动过多并行执行服务的风险:
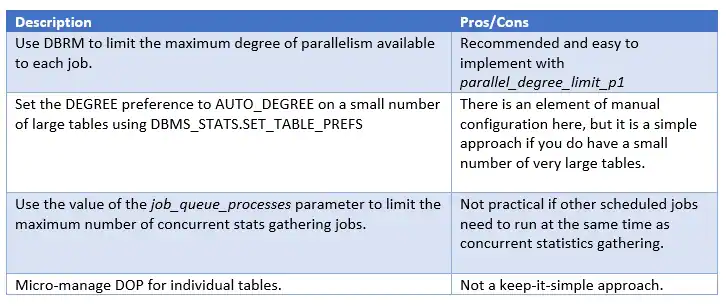
允许自动统计信息收集任务使用并发:
exec dbms_stats.set_global_prefs('CONCURRENT','AUTOMATIC')设置全局性的AUTO_DEGREE:
exec dbms_stats.set_global_prefs('DEGREE', DBMS_STATS.AUTO_DEGREE)
或者,针对特定的大表:
exec dbms_stats.set_table_prefs(user, 'BIG_TABLE', 'DEGREE', DBMS_STATS.AUTO_DEGREE)总结:
一般来说,如果你有很多的大表,方法1最有可能让你快速收集。如果你有大量空闲的机器资源和大量的小表,推荐方法2。
方法3需要更加小心,避免启动过多的并行执行服务。
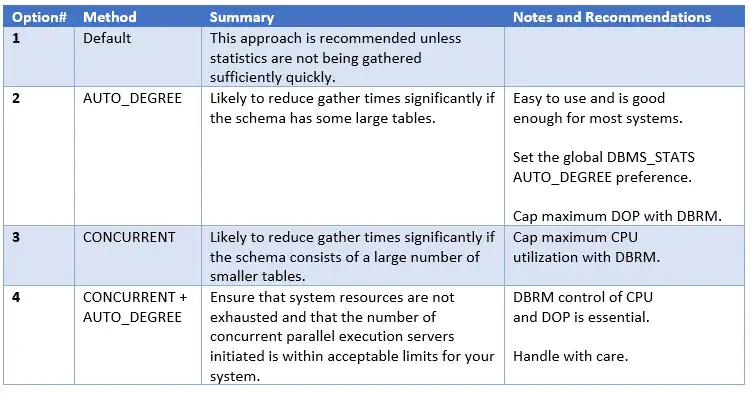
原文有方法对应资源使用情况的测试,可以参考
原文链接:https://blogs.oracle.com/optimizer/post/how-to-gather-optimizer-statistics-fast